H.264 作为新一代的视频编码标准有着优异的性能,广泛应用于视频会议、视频点播、数字电视广播、数字视频存储以及消费电子等多个领域。与H.263或MPEG-4 相比,同等图像质量下,码率能降低一半左右,但是算法复杂度高。
H.264 标准在低码率的情况下能产生高质量的画面,主要就是采用了自适应的环路滤波。H.264 采用了基于树状结构的块的运动补偿,基于块的运动补偿能很好地降低码率, 但这同时也引起了方块效应。
由此H.264 采用了一种自适应的滤波算法,能够很好地降低方块效应, 但同时也带来了极大的运算复杂度。在H.264 中,滤波后的数据将作为下一帧的参考帧,因此又称为环路滤波。研究表明:在H.264 解码过程中其中运动补偿(MC)约占30%,环路滤波(DF)约占20%的解码时间,因此很好的设计MC 与DF 对解码器的性能至关重要。
1 滤波过程用到的数据
H.264 中, 在MBAFF 情况下的解码中宏块都是以宏块对的形式出现。因此在存储数据的时候也考虑到以一个宏块对的数据为单位进行存储。在一个宏块对中, 滤波时整个过程中需要操作的数据如图1 所示。其中每一个小方块表示一个4×4 像素的block,在滤mb_up 宏块时需要用到up 所指的数据,本次设计支持MBAFF,在滤波过程中需要进行帧与场的转化,因此要用到上面二行的block。在滤波最左边的block时需要用到图中left 所指示的一列数据。

图1 滤波中的数据
2 DRAM 的规划与设计
DRAM 是一种成本低、容量大、应用广泛的存储介质, 对大规模数据的操作十分迅速。然而由于DRAM 中有一个Row 的概念。在操作不同的Row 的情况下DRAM 要先关闭当前的Row, 同时再激活所需的Row,这样就造成了很多的overhead。试想读取同一Row 的10 个数据与分别处于10 个Row 的10个数据,后者的时间耗费将会是前者的5~6 倍。因此DRAM 不适合对随机的分散的数据存取。
由于Row 的存在, 对DRAM 中的数据结构的设计就显得尤为重要。要尽量减少不同Row 之间的访问,这样才能提高数据的存取效率。本次设计中采用位宽为64 位的DRAM, 恰好可以存放8 个点的像素值。一幅图像亮度Y、色度UV 分别存放在一个连续的空间中。
H.264 解码后的最后图像存入DRAM 中,显示模块不断的从DRAM 中取出数据送到显示器, 运动补偿单元也要从DRAM 中取出参考帧的数据。因此DRAM 的带宽尤为紧张。合理地分配DRAM 的带宽是设计中要考虑的一个重要方面。由于很多模块都要求对DRAM 进行操作, 为了有效地对DRAM 进行管理,设置了DRAMCONtrol 模块来对DRAM 进行控制。
3 DRAMControl 模块的设计
DRAMControl 模块控制着DRAM 与外面其它模块的交互,是DRAM 与外部其它模块的接口。主要的功能包括DRAM 的自动刷新、DRAM 的命令的产生等。因为DRAM 工作时的状态多,本次设计中采用状态机的方式来实现。其中状态图如图2 所示。

图2 DRAMControl 中的状态转移图
设计中采用了均匀刷新的方式, 每隔一定的时间, 经过“IDLE → PRECHALL → AUTORF →IDLE”的过程就完成一次刷新。状态转换的主体是读写操作过程,判决状态(Decision)占用一个时钟周期判断当前操作所要执行的Row 是否处于激活状态,如果没有激活则要先关闭当前处于激活状态的Row,再激活所需的Row(通过PRECH 和ACT 状态完成);如果已经激活,则直接进行读写操作。对于写操作,针对H.264 中滤波结束后要更新上边宏块,左边宏块以及自身宏块的数据来设计了WRITEUP 或WRITELEFT 和WRITE 这三个状态写入DRAM,而且这些状态之间实现了时间上的无缝连接,构成了一个完整连贯的BurST 写操作; 如果上边宏块的数据或左边宏块的数据块处于与待滤波宏块的数据块不同的Row 中,则在WRITEUP 或WRITELEF 状态实现不在本Tile 中数据块的写操作,这种情况的写效率显然比在同一个Row 中的时候下降了, 但这是不可避免的, 当宏块处于本Row 的最左边或最上边的时候,其上边宏块数据或左边宏块数据块必然是属于其它Row 的。本次设计中,DRAM 一个地址存本block 和下一个block 的同一行, 因此这样就最多的避免了跨Row 的操作。对于其它情况的写操作,使用WRITE 状态完成。[page]
4 SRAM 的规划与设计
在H.264 解码过程中,数据由熵解码经过运动补偿后再通过环路滤波最终送到存储器中,之后显示解码芯片从存储器中不断的提取数据送到显示器上,最终完成数据的解码,如图3 所示。在滤波的过程中,宏块中的数据频繁地被调用。而SRAM 的读写速度快的特点能很好地适用这一要求。因为在H.264 中最小的单元为block,运动矢量等都是以block 为单位来进行传递。因此以block 为单位来进行数据的存取会带来很大的方便。本设计中各个SRAM 每一个地址存放一个block 单元的数据(16 个像素点),即采用128bit 的SRAM。
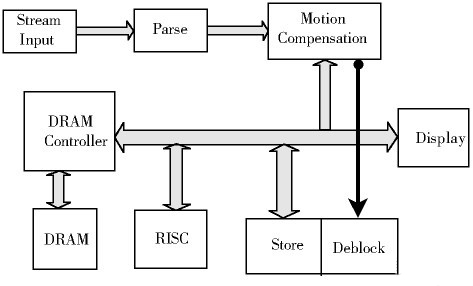
图3 DRAM 与其它模块之间的数据交互
在H.264 中运动补偿结束后的数据交由环路滤波运算后写入DRAM, 我们把写入DRAM 的这一过程称为Store 过程,由Store 模块负责。由图3 可以看出MC 与Deblock 是一个串联的关系。为了提高解码的速度,我们将运动补偿与环路滤波并行执行,即当前解码的结束并不以环路滤波的结束为标志,而当前宏块的运动补偿一结束我们就可以开始下一个宏块的解码。经过大量的实验发现:MC 的时间远比block的时间大很多,当后一个模块要进行滤波时滤波模块早已准备完毕。最后对存储模块我们也同样的用并行的思想来加快解码的速度。结果当作MBx 的MC 时,做MB(x-1)的滤波,同时MB(x-2)存储。此时需要注意MB(x-1)的滤波和MB(x-2)的存储并不是同时开始。因为做MB(x-1)的滤波时也会影响到MB(x-2)中的数据。
因此我们要等MB(x-1)的第一条垂直边滤波结束后才开始MB(x-2)的存储。具体的时间关系如图4 所示。
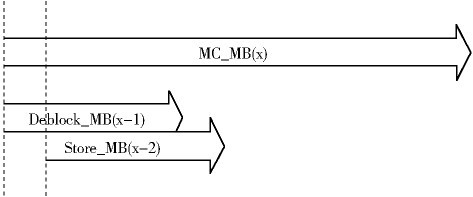
图4 各个模块之间的时序关系图
(1)滤波前数据的存储及滤波结束后数据的存储
由于设计中采用此种流程,我们需要3 片SRAM来存储MC 的运算结果。这3 片SRAM 交替地进行MC、Deblock 和Store。我们称这3 片SRAM 为SRAM_MB,滤波结束后的数据也存储在此SRAM 中,在经Store 模块将此数据存储到DRAM 中去。因为滤波结束时,恰好原来SRAM_MB 中的数据也已经成为无效数据。这里需要注意,由于有帧场自适应的情况存在,滤波结束后的数据如果帧场情况不一样,我们还需要根据数据不同的情况进行适当的帧场转化,之后再将数据存入DRAM。
(2)垂直滤波后的数据的存储
我们都知道滤波过程是一个先垂直后水平的过程,因此我们需要有一片SRAM 来存储水平滤波的结果。这片SRAM 就叫SRAM_BUFFER。因为水平滤波时正在从SRAM_MB 中读取数据,同一时间不能同时向SRAM 中读取、写入数据。因此我们用SRAM_BUFFER 来暂存垂直滤波结束后的数据。水平滤波时则从SRAM_BUFFER 中读取数据, 滤波后存储到SRAM_MB 中。
5 总结
本文对H.264 解码芯片中的滤波、存储模块作了深入的分析。并根据各个时间数据的特点作相应的存储器的设计, 这种设计方法经过验证能很好地处理H.264 中滤波及存储时的数据的调度。整个滤波过程约52 个周期就可以完成。在MBAFF 情况时各种数据的转化时钟周期控制在70 个以内。这种设计符合要求,并在FPGA 上验证后能够正常的运行,运行时钟达到60MHz,能实时地完成对高清图像的解码。