实现 H.264/AVC 编码标准所需的算法计算复杂度、数据局部性,以及算法和数据并行性,常常会直接影响系统级别的整体架构决策。这种影响又会决定在广播、视频编辑、电话会议以及消费电子领域开发H.264/AVC解决方案所需的最终开发成本。
复杂度分析
为了实现实时 H.264/AVC 标准清晰度 (SD) 或高清晰度 (HD) 分辩率编码解决方案,系统架构师常常需要使用多个 FPGA 和可编程 DSP。为了说明所需计算的巨大复杂度,先探讨一下 H.264/AVC 编码器的典型运行时的周期要求。H.264/AVC 编码器基于由联合视频工作组(JVT)提供的软件模型,该工作组由来自 ITU-T 的视频编码专家组 (VCEG) 和 ISO/IEC 的运动图像专家组 (MPEG) 的专家组成。
采用Intel的VTune软件,在 Intel Pentium III 1.0 GHz 通用 CPU、512 MB 内存的平台上运行,按照主要配置编码解决方案实现 H.264/AVC SD,需要约 1,600 BOPS(每秒十亿次运算)。

表 1 显示了基于 Pentium III 通用处理器架构的 H.264/AVC 编码器的复杂度的典型情况。请注意,在表 1 中,运动估计、宏块/块处理(包括模式决策),以及运动补偿模块是基本候选硬件加速单元。
然而,单凭计算复杂度并不能决定一个功能模块是否应映射为硬件或是使其保持为软件。为了评估在由 FPGA、可编程 DSP或通用主处理器混合组成的平台上实现 H.264/AVC 编码标准时,软件和硬件分割的可行性,需要分析将会影响整体设计决策的大量架构问题。
数据局部性。
在同步设计中,按照特定的顺序和粒度访问内存,同时根据延迟、总线竞争、对准、DMA 传输率以及所用内存的类型(如 ZBT 内存、SDRAM和 SRAM 等)使时钟周期数降至最小的能力至关重要。数据局部性问题主要是由数据单元和算术单元(或处理引擎)之间的物理接口体现的。
数据并行性。
大多数信号处理算法都是对高度并行的数据进行操作(如 FIR 滤波)。单指令多数据 (SIMD) 和向量处理器对可被并行化或做成向量格式(或长数据宽度)的数据具有较高的处理效率。
FPGA可通过提供大量块 RAM 支持大量极高总计带宽要求来实现这一点。在新的 Xilinx Virtex-4 SX器件中,块 RAM 的数量与 Xtreme DSP的逻辑片数紧密匹配(例如,SX25具有128个块RAM,128个DSP逻辑片;SX35具有192个块 RAM,192个DSP 逻辑片;SX55具有320个块 RAM,512个DSP逻辑片)。
信号处理算法并行机制。
在典型的可编程 DSP 或通用处理器中,信号处理算法并行机制通常是指指令级并行 (ILP)。超长指令字 (VLIW) 处理器是此类采用ILP的机器中的一个例子,它将多条指令(ADD、MULT 及 BRA)组合起来,在一个周期内执行。处理器中高度流水线化的执行单元也是实现并行机制的典型硬件示例。现在已经有可编程DSP采用这种架构(如TI的 TMS320C64x)。
但是,并非所有算法都能使用这种并行机制[page]。递归算法,如 IIR 滤波、MPEG 1/2/4 中的变长编码 (VLC)、上下文自适应变长编码 (CAVLC),以及 H.264/AVC 中的上下文自适应二进制算术编码 (CABAC),当映射到这些可编程 DSP 时,均无法达到最优且效率不高。这是因为数据递归阻碍了 ILP 的有效利用。作为取代方案,可在FPGA 结构中有效地构建专用硬件引擎。
计算复杂度。
可编程 DSP 受计算复杂度的限制,可通过处理器的时钟速率来度量。在FPGA中实现的信号处理算法通常为计算密集型算法。其中的例子有运动估计中的绝对差值和 (SAD) 引擎以及视频缩放。
通过将这些模块映射到 FPGA 中,主处理器或可编程DSP就可有额外的周期来处理其他算法。此外,FPGA 结构还可以具有多时钟域,从而允许选择性硬件模块根据各自的计算要求使用独立的时钟速度。
理论上质量的最优性。
当且仅当对复杂度没有限制时,任何基于速率失真曲线的理论最优解决方案均可实现。在可编程 DSP 或通用处理器中,计算复杂度常受可用时钟周期的限制。而 FPGA 则相反,通过对硬件引擎的多重实例化,或提高结构中块 RAM 和寄存器组的利用率,实行数据和算法并行机制,从而提供更高的灵活性。
可编程 DSP 或通用处理器通常受每个周期发出的指令数、执行单元中的流水线级数以及完全馈给执行单元所需最大数据宽度的限制。在可编程 DSP 中,受每个任务可用周期数的限制,视频质量常常大受影响。而在 FPGA 结构中,硬件资源则可得到完全分配(三步和完全搜索运动估计对比)。
使用FPGA 实现功能模块
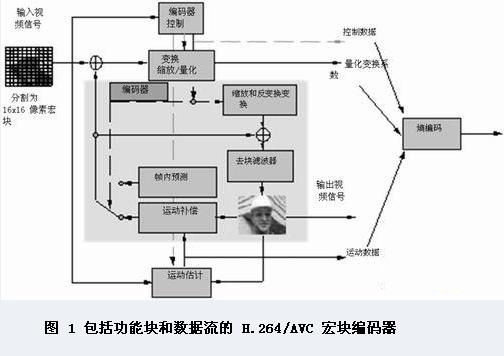
图 1 为定义了主功能块和数据流的整个 H.264/AVC 宏块级编码器。H.264/AVC 标准的主要优势在于能够通过以不同的方式和方向分析像素冗余,预测要编码的图像内容的值,而这种分析以前从未在其他标准中进行过。但与以前的标准相比,其复杂度和内存访问带宽增加了4倍。
改进预测方法
下面重点分析一下在 H.264/AVC 视频编码设计中实现其增强编码效率的主要特点,根据前文讨论过的设计准则对这些功能模块进行评估。
四分之一像素精度(Quarter-pixel-accurate) 运动补偿。
以前的标准采用二分之一像素运动向量精度。新设计通过采用四分之一像素运动向量精度对此进行了改善。二分之一像素位置的预测值是通过沿横向和纵向采用一个一维6抽头 FI[FS:Page]R 滤波器 [1, -5, 20, 20, -5, 1]/32 计算得到的。
四分之一像素位置的预测值是通过将全像素和二分之一像素位置的采样值进行平均得到的。这些二次采样内插运算可在 FPGA内的硬件中高效地实现。
小块尺寸可变块大小运动补偿。
该标准在 16×16 像素宏块尺寸中为铺瓦结构 (tiling structure) 提供了更多的灵活性。它允许使用 16×16、16×8、8×16、8×8、8×4、4×8 和 4×4 子宏块尺寸。
由于给定 16×16 宏块铺瓦结构的组合增多,因此要找到一个速率失真优化铺瓦解决方案需要很高的计算强度。这一额外特性为运动估计、细化和模式决策过程中所用的计算引擎增加了巨大负荷。
环中自适应去块(deblocking) 滤波。
去块滤波器已经在 H.263+ 和 MPEG-4 第 2 部分的实现中作为后处理滤波器被成功采用。在 H.264/AVC 中,去块滤波器将在运动补偿环路中移动,对在预测和解码过程中的残留差值编码阶段造成的块边缘[page]进行滤波。滤波对 4×4 块和 16×16 宏块边缘均可进行,两个边上的两个像素可能会被一个三抽头滤波器更新。滤波器系数或强度由内容自适应非线性滤波器决定。
帧内编码有向空间预测。
当无法采用运动估计时,可以采用帧内有向空间预测来估计空间冗余。这种技术通过从相邻块沿预先定义的一组方向向相邻像素外插来预测当前块。然后就可以对预测块和实际块之间的差值进行编码了。
这种方法在存在空间冗余的平面背景中特别有用。对于 Intra_4×4 预测,总共有九种预测方向;对于 Intra_16×16,则有4种预测方向。注意,在 Intra_4×4情况下,由于数据因果性,将导致对当前块上边和左边相邻的 13 个像素值的快速内存访问。对于 Intra_16×16,每边将使用 16个像素来预测一个 16×16 块。
多参考图像运动补偿。
H.264/AVC 标准为帧间编码提供了多参考帧选项。除非参考图像的数量为1,否则必须指定参考图像在多图像缓冲区内的索引位置。多图像缓冲区的尺寸决定编码器和解码器中内存的使用情况。这些参考帧缓冲区必须在编码器的运动估计和补偿阶段分别访问。
加权预测。
JVT 认为在对一些有衰弱现象的视频图像进行编码时,采用加权运动补偿预测可以极大地改善编码效率。
改善编码效率
除了预测方法得到改进以外,该标准设计的其他部分也对编码效率的改善进行了增强。下面两个附加特性最容易对基于关于软件和硬件分割的设计准则的整体系统架构产生影响。
小块尺寸,层次化,精确匹配反变换和短字长变换。
同其他标准一样,H.264/AVC 也是对运动补偿预测残留施加变换编码。
但是,与以前采用 8×8 离散余弦变换 (DCT) 的标准不同,这种变换是施加于 4 x 4 块上,并且采用 16 位整数格式,可以精确地进行反变换。小块有助于减小分块和振铃结果,而精确整数规范则消除了编码器与反变换中的解码器之间的一切不匹配问题。
此外,还采用了一种基于阿达玛矩阵 (Hadamard matrix) 的附加变换,以实现已变换块的 16 个 DC 系数的冗余。与 DCT 相比,所有整数变换矩阵中只包含从 -2 到 2 之间的整数。这样,只使用低复杂度的移位寄存器和加法器就可以通过 16 位算术计算变换和反变换。
算术和上下文自适应熵编码。
有两种熵编码方法:一种是基于上下文自适应切换变长编码集 (CAVLC) 的低复杂度技术,一种是计算要求更高的基于上下文的自适应二进制算术编码 (CABAC) 算法。
CAVLC 是 H.264/AVC 的基本熵编码方法。其基本编码工具包括一个结构化 Exp-Golomb 编码 VLC,它通过单独定制的映射,可应用于除与量化变换系数有关的语法元素以外的所有语法元素。CABAC则采用了一种更为复杂的编码方案。
首先,根据一种预定义的扫描模式,将变换系数映射到一个 1 维数组。量化后,块将只包含一些重要的非零系数。
根据该统计结果,使用5个数据元素来传递特征 4 × 4 块的量化变换系数的信息。使用 CABAC 可进一步改善熵编码的效率。
CABAC 中的两个部分。规定算术编码内核引擎及其相关的概率估计是免乘法、低复杂度方法,只能使用移位和查找表。自适应编码的使用使之能够与非静止符号统计适应。通过采用根据前面编码语法元素进行[page]估计从而在条件概率模型间切换的上下文建模方法,CABAC 可获得比 CAVLC 低 5~15% 的位速率。
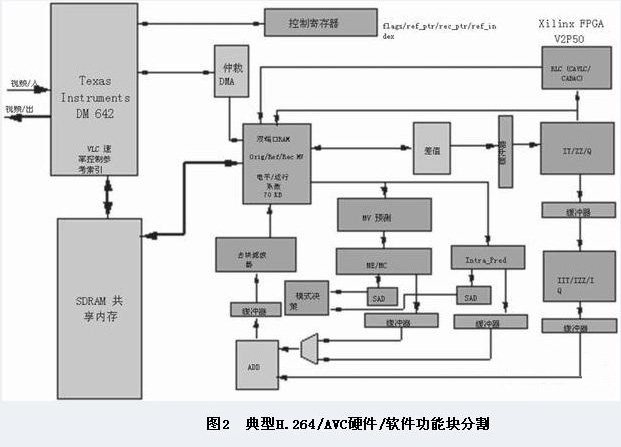
图 2 显示了 H.264/AVC SD 视频编解码器系统级功能块的典型分割。该解决方案基于针对 TI公司的TMS320DM642 DSP 的 Spectrum Digital EVM DM642 评估模块,结合 Xilinx XEVM642- 2VP20 Virtex-II Pro或XEVM642-4VSX25 Virtex-4子插件板实现。
结束语
以最优模式使用时,与以前的视频编码标准(如 MPEG-4 第 2 部分和 MPEG-2)相比,H.264/AVC 标准的编码工具可在很宽的位速率和分辩率范围内使编码效率提高约 [FS:Page]50%。但是,当分辩率比源输入格式 (SIF) 高时,算法极为复杂。
参考文献
“联合视频规范国际标准 ITU-TU 建议草案和最终草案 (ITU-T Rec. H.264/ISO/IEC 14 496-10 AVC),”ISO/IEC MPEG 与 ITU-T VCEG 联合视频工作组 (JVT) ,JVT-G050, 2003
A. Luthra、G.J. Sullivan 和 T. Wiegand,2003 年 7 月。“有关 H.264/AVC 视频编码标准的专门问题”。 IEEE Trans.电路系统视频技术 13(7): 557-725