
不管是修改现有应用程序还是编写全新代码,设计并行应用程序所面临的挑战要比顺序程序艰巨得多。
毫无疑问,目前常用的高层抽象和API极大简化了设计过程,但大多数方法仍需要人工识别并行代码部分,并要考虑竞态条件以及并行任务之间的同步等等问题。随着单颗芯片上的CPU内核数量不断增加,想要充分利用多核硬件优势的相关应用,很可能会遭遇并行编程的痛苦。
基于数据流的一类编程语言,不仅能显著简化针对今天的多内核处理器开发代码的过程,而且能够成为发挥未来更多内核CPU优势的关键策略。
顺序搜索
在寻求并行编程挑战的解决方案时,首先认识到目前编程语言和并行处理器架构之间的不匹配,是很有帮助的。
随着处理器硬件的发展,嵌入式工程师和计算机科学家编写的程序通常都与硬件结构直接相关。在最基本的层次,这种概念在汇编语言中非常突出,因为在汇编语言中都是直接操作处理器的寄存器。
现代编程语言
现代编程语言已经提升了其抽象层次,除了人工线程操作外,还提供基于任务的API和并行结构。但嵌入式编程有一个方面基本保持没变:编程是按顺序逐行方式进行的,所模拟的是在大多数微处理器上单线程执行的顺序行为。
这与流程图方法有很大区别,后者正是许多工程师针对某项应用展开头脑风暴时所追求的。流程图方法不是立即集中处理按照CPU架构要求的一组顺序步骤,而是让编程人员更直接地解决他们想要解决的问题,方法是集中精力于操作数据需要的算法上,以及这些算法之间的从属性。
另外,流程图是以直观可视方式表达并行过程(没有数据依赖性的过程)的一种自然选择。
传统的做法要求编程人员在CPU实现之前将流程图部分转换为顺序语句——这是不仅费时,而且对并行任务来说相当困难的任务。然而,经过十多年研发推出的编程语言,可以直接编码函数和数据依附信息,从而使转换步骤变得不再必要。参考数据流语言可以发现,它们有一个无法被忽略的重要优点:自动识别代码的并行部分并在多内核处理器上予以执行的能力。
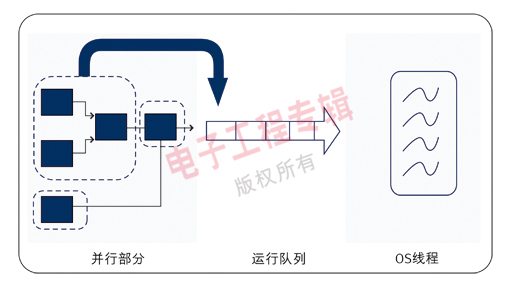
简而言之,传统编程语言要求编程人员将他们的想法适应顺序执行模型,并人工识别代码的并行部分。而今天的数据流解决方案,能够使用智能编译器检测并行机制(图2),然后选择如何最佳调度顺序型CPU指令。这是一项根本性的改变,它能让开发人员集中精力解决手头的问题,而不是去处理底层硬件。
为您推荐
我们需要新的编程语言?你可能认为并不需要,但是如果你去了解最近的趋势,你可能会改变你的想法。为什么Google采用GO和DART两种编程语言?为什么IBM、Cray、RedHat分别创造了X10、Chapel和Ceylon三种语言?未来,这10种编程语言(DART、Ceylon、GO、F#、OPA、Fantom、Zimbu、X10、Haxe、Chapel)是否能否撼动IT。新的编程语言是为了满足某些人的创作冲动还是新编程方式的技术演进?回顾历史如果你回头看看,我们可以看出新语言的爆发将历史分为3个时期,每个时期都链接到技术演进的临界点。云计算是否会用到这些语言?如果你分析这些新语言背后的故事,
数据流是数据在稳定的高速传输,这种速率足以支持类似高清电视(HDTV)或者在一台计算机内连续地将备份拷贝到工作流的存储媒介中这类的应用程序。数据流需要足够的带宽,实时的人类对数据的感知,确保足够的数据能够流畅地接受而没有明显的时间滞后的能力。

