
前言:
Fluid 是一个开源的 Kubernetes 原生的分布式数据集编排和加速引擎,主要服务于云原生场景下的数据密集型应用。在 Fluid 上使用和部署 JindoRuntime 实现数据集的可见性、弹性伸缩、数据迁移、计算加速等,并流程简单、兼容原生 k8s 环境、可以开箱即用。同时深度结合对象存储特性,使用navite框架优化性能,并支持免密、checksum校验等云上数据安全功能。
01JindoRuntime
如果要了解Fluid的JindoRuntime,先要介绍JindoFS。它是JindoRuntime的引擎层。
JindoFS 是阿里云针对 OSS 开发的自研大数据存储优化引擎,完全兼容 Hadoop 文件系统接口,给客户带来更加灵活、高效的计算存储方案,目前已验证支持阿里云 EMR 中所有的计算服务和引擎:Spark、Flink、Hive、MapReduce、Presto、Impala 等。JindoFS 有两种使用模式,块存储(Block)模式和缓存(Cache)模式。
Block 模式将文件内容以数据块的形式存放在 OSS 上并在本地可选择使用数据备份来进行缓存加速,使用本地的namespace 服务管理元数据,从而通过本地元数据以及块数据构建出文件数据。Cache 模式将文件存储在 OSS上,该模式兼容现有的 OSS 文件系统,用户可以通过 OSS 访问原有的目录结构以及文件,同时该模式提供数据以及元数据的缓存,加速用户读写数据的性能。使用该模式的用户无需迁移数据到 OSS,可以无缝对接现有 OSS 上的数据,在元数据同步方面用户可以根据不同的需求选择不同的元数据同步策略。
在 Fluid 中 JindoRuntime 也是使用 JindoFS 的 Cache 模式进行远端文件的访问和缓存,如您需要在其他环境单独使用 JindoFS 获得访问 OSS 的能力,您也可以下载我们的 JindoFS SDK 按照使用文档进行部署使用。
JindoRuntime 来源于阿里云EMR团队自研 JindoFS 分布式系统,是支撑 Dataset 数据管理和缓存的执行引擎实现。Fluid 通过管理和调度 Jindo Runtime 实现数据集的可见性、弹性伸缩、数据迁移、计算加速等。在 Fluid 上使用和部署 JindoRuntime 流程简单、兼容原生 k8s 环境、可以开箱即用。深度结合对象存储特性,使用 navite 框架优化性能,并支持免密、checksum 校验等云上数据安全功能。
02JindoRuntime 的优势
JindoRuntime 提供对 Aliyun OSS 对象存储服务的访问和缓存加速能力,并且利用 FUSE 的 POSIX 文件系统接口实现可以像本地磁盘一样轻松使用 OSS 上的海量文件,具有以下特点:
1、性能卓越
OSS的读写性能突出:深度结合 OSS 进行读写效率和稳定性的增强,通过 native 层优化对 OSS 访问接口,优化冷数据访问性能,特别是小文件读写分布式缓存策略丰富:支持单TB级大文件缓存、元数据缓存策略等。在大规模AI训练和数据湖场景实测中有突出的性能优势。
2、安全可靠
认证安全:支持阿里云上 STS 免密访问和K8s原生的秘钥加密数据安全:checksum 校验、客户端数据加密等安全策略,保护云上数据安全和用户信息等。
3、简单易用
支持原生 k8s 环境,利用自定义资源定义,对接数据卷概念。使用部署流程简单,可以开箱即用。
4、轻量级
底层基于 c++ 代码,整体结构轻量化,各种 OSS 访问接口额外开销较小。
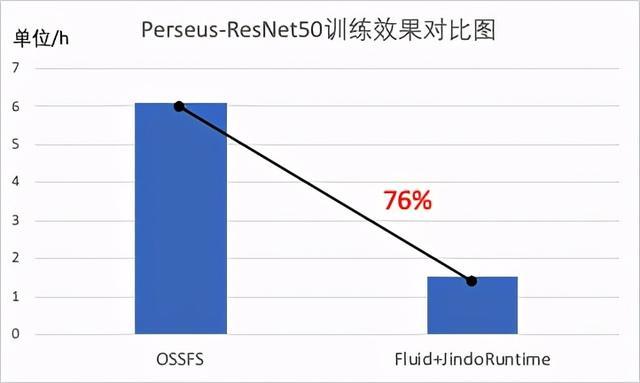
03JindoRuntime 性能
我们使用 ImageNet 数据集基于 Kubernetes 集群并使用 Arena 在此数据集上训练 ResNet-50 模型,基于 JindoFS 的 JindoRuntime 在开启本地缓存的情况下性能大幅度优于开源 OSSFS,训练耗时缩短了76%,该测试场景会在后续文章中进行详细介绍。
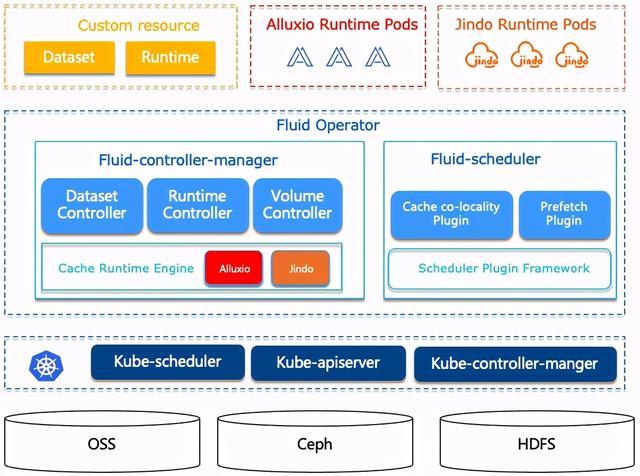
04 Fluid
Fluid 是一个开源的 Kubernetes 原生的分布式数据集编排和加速引擎,主要服务于云原生场景下的数据密集型应用,例如大数据应用、AI应用等。通过 Kubernetes 服务提供的数据层抽象,可以让数据像流体一样在诸如 HDFS、OSS、Ceph 等存储源和 Kubernetes 上层云原生应用计算之间灵活高效地移动、复制、驱逐、转换和管理。而具体数据操作对用户透明,用户不必再担心访问远端数据的效率、管理数据源的便捷性,以及如何帮助 Kuberntes 做出运维调度决策等问题。用户只需以最自然的 Kubernetes 原生数据卷方式直接访问抽象出来的数据,剩余任务和底层细节全部交给 Fluid 处理。
Fluid 项目当前主要关注数据集编排和应用编排这两个重要场景。数据集编排可以将指定数据集的数据缓存到指定特性的 Kubernetes 节点,而应用编排将指定该应用调度到可以或已经存储了指定数据集的节点上。这两者还可以组合形成协同编排场景,即协同考虑数据集和应用需求进行节点资源调度。
然后介绍 Fluid 中 Dataset 的概念,数据集是逻辑上相关的一组数据的集合,会被运算引擎使用,比如大数据的 Spark,AI场景的 TensorFlow,而关于数据集智能的应用和调度会创造工业界的核心价值。Dataset 的管理实际上也有多个维度,比如安全性,版本管理和数据加速。
我们希望从数据加速出发,对于数据集的管理提供支持。
在 Dataset上面我们通过定义 Runtime 这样一个执行引擎来实现数据集安全性,版本管理和数据加速等能力,Runtime 定义了一系列生命周期的接口,可以通过实现这些接口来支持数据集的管理和加速,目前 Fluid 中支持的 Runtime 有 AlluxioRuntime 和 JindoRuntime 两种。Fluid 的目标是为 AI 与大数据云原生应用提供一层高效便捷的数据抽象,将数据从存储抽象出来从而达到如下功能:
1、通过数据亲和性调度和分布式缓存引擎加速,实现数据和计算之间的融合,从而加速计算对数据的访问。
2、将数据独立于存储进行管理,并且通过 Kubernetes 的命名空间进行资源隔离,实现数据的安全隔离。
3、将来自不同存储的数据联合起来进行运算,从而有机会打破不同存储的差异性带来的数据孤岛效应。
为您推荐

云原生爆发期到来时至今日,对于企业用户而言,云原生和混合云的概念已深入人心,对其应用和部署业已成为一种新常态。相关数据显示,当前93%的企业正在采用多云策略,而多云中部署混合云的比例高达87%;与之同时,伴随云的普及,云原生应用则成为企业云时代的现实选择。青云QingCloud 应用及容器平台研发总监周小四介绍,目前,Kubernetes在全球化方面已


