
2020全球分布式云大会于12月17日-18日召开,阿里云分布式数据库技术专家傅宇出席大会并发表精彩演讲。
“ 为期两天的Distributed Cloud|2020全球分布式云大会,为5G商用时代的到来,在新一轮云计算技术变革的关口,呈现出分布式云生态全景,影响2021年分布式云战略科技趋势,共享新商业引擎,共寻亿万级苍穹,开创未来新篇。
”在12月18日下午的“分布式数据论坛”上,阿里云分布式数据库技术专家傅宇带来题为《PolarDB-X分布式云原生数据库》的精彩演讲。

01 什么是PolarDB-X
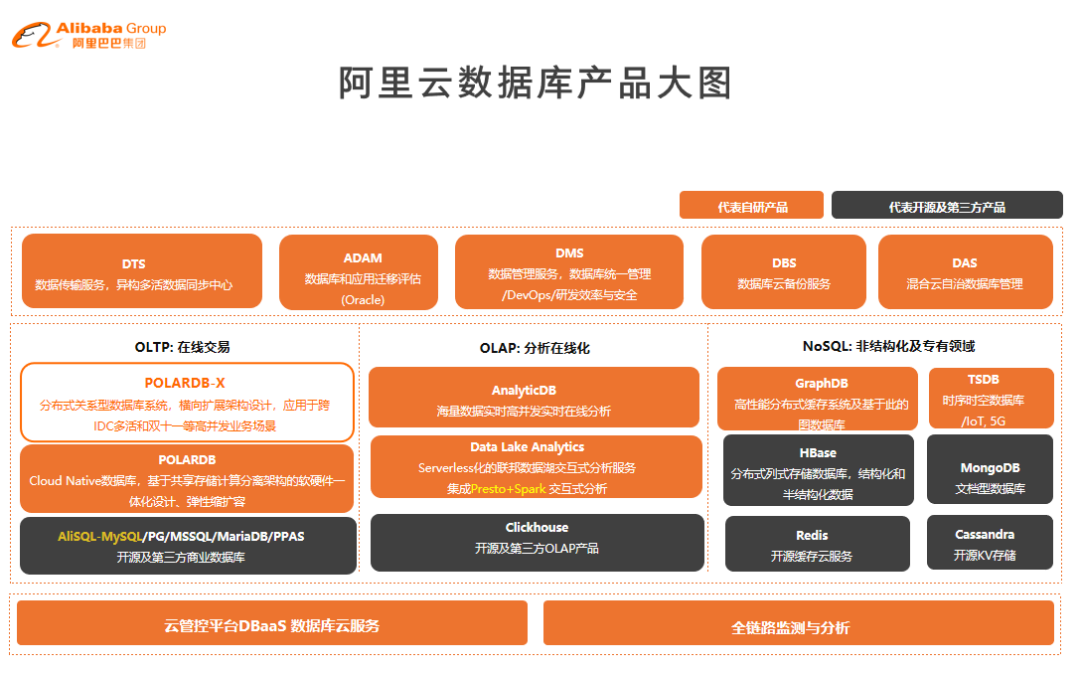
傅宇首先对PolarDB-X产品做了介绍,阿里云数据库产品主要分为三类,分别是OLTP、OLAP、MySQL。今天介绍的PolarDB-X 是一款分布式数据库,它主要解决数据库的扩展性问题。
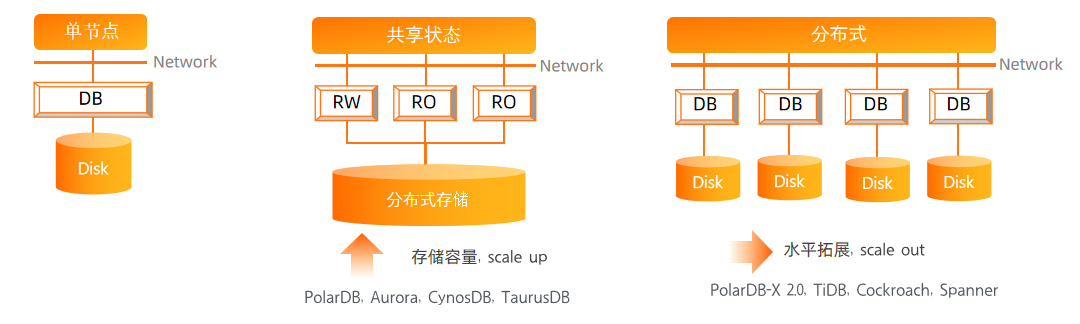
图中为常见的几种数据库架构。最左边的是常见的单机数据库,它的计算资源和存储资源受到单个节点的容量限制。中间为共享存储数据库,它将开源数据库(如MySQL)的底层存储替换成共享的分布式存储,从而实现容量的可扩展性,并且可以做到完全兼容开源数据库。但是由于上层组件保留了单机数据库结构,仍然受到单个节点的性能限制。最右侧是以PolarDB-X为代表的分布式数据库架构,所有节点之间互相不共享资源,节点间通过网络进行通讯,无论是存储还是计算资源,只要添加机器就可以了,具有良好的可扩展性。

PolarDB-X的愿景就是把各种架构的优势结合到一起。Sharding on MySQL的特点是简单轻量,但是扩容的时候需要接入很多外部工具;NewSQL解决了扩容问题;Cloud Native DB可以做到存储容量的弹性扩展。
02 PolarDB-X优势整合
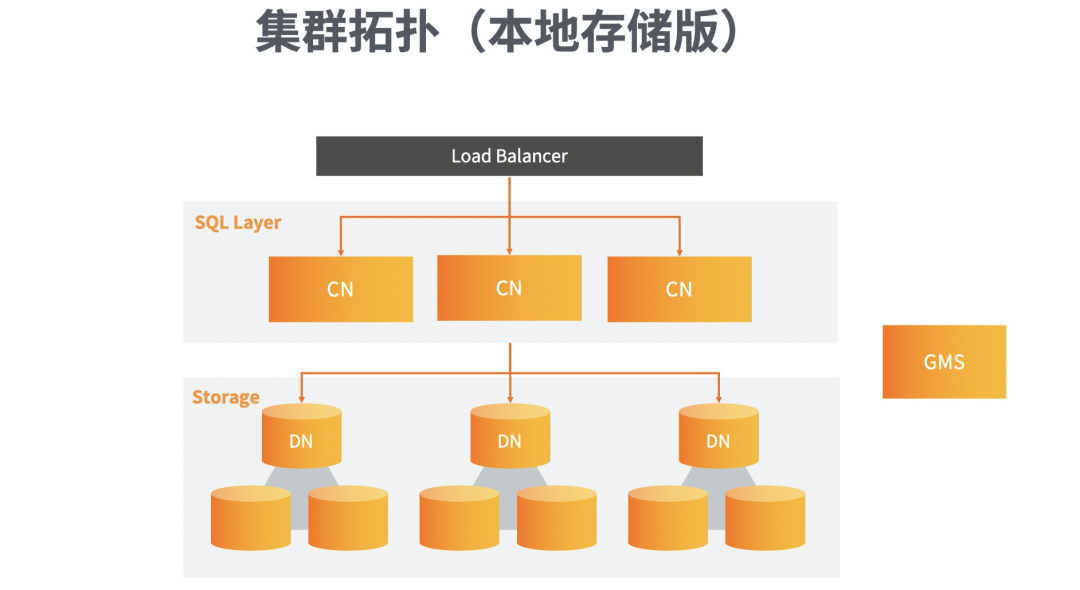
随后,傅宇分析了PolarDB-X是如何整合上述优势的。PolarDB-X分为本地存储版和共享存储版两种架构。上图中是本地存储版的架构,集群节点分为SQL层和存储层,SQL 层中的CN节点负责解析优化和执行用户的查询,存储节点简称DN,这里采用本地部署的方式,通过Paxos协议来保持数据的一致性和高可用性。
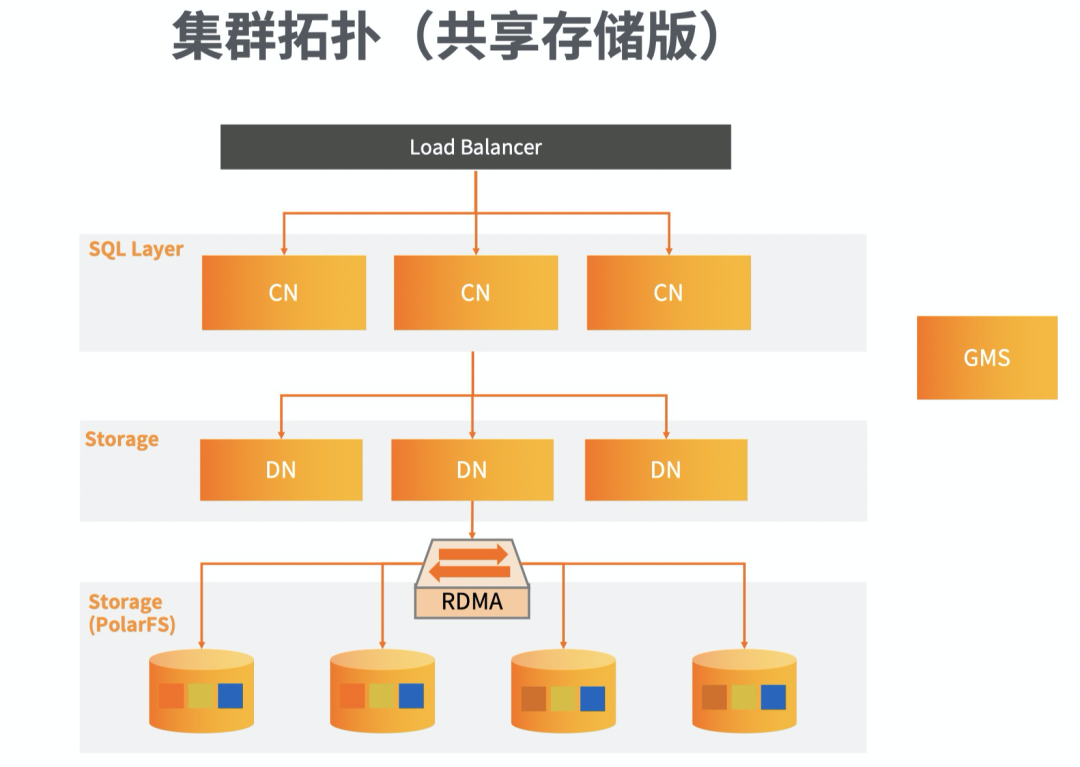
PolarDB-X也支持共享存储架构。与本地存储对比,主要区别是DN节点替换成了分布式共享存储(PolarFS),因此存储层能够借助共享存储的优势做到弹性拓展。相比PolarDB的一写多读,但PolarDB-X中的每个DN节点都可以提供读写访问,这是因为上层的CN节点已经对数据进行了分区,每个DN节点负责其中几个分区,彼此的数据没有交集。只要增加新的DN节点就能够实现对存储层的扩容。
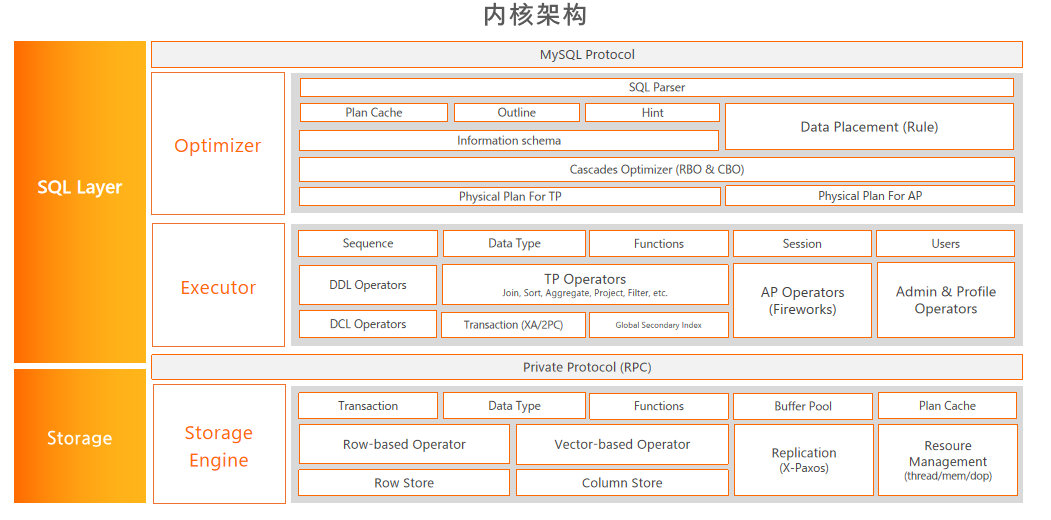

PolarDB-X的核心特性是六个:高可用、高兼容性、高扩展性、HTAP、极致弹性、开放生态。拥抱MySQL生态是PolarDB-X的重要理念,MySQL所有相关工具、阿里云的DTS、DMS等工具都可以直接在PolarDB-X上使用。
03 PolarDB-X核心技术
之后,傅宇对几项比较重要的技术做了详细介绍。首先是大家最关心的高可用的问题,这里使用阿里云自研的高性能的Paxos库——X-Paxos,它支持Logger、Learner角色。Logger节点只负责持久化log而提供服务,因此对硬件配置要求相对较低。Learner角色可以在同步数据的同时不参与投票,通常用它来实现只读节点。除此以外还有其他一些企业级特性,比如多数派权重支持、多流并发、log的乱序确认等。
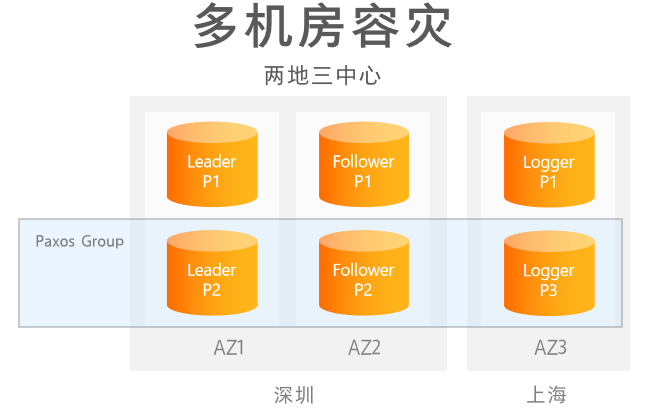
通过Paxos两地三中心的架构,可以做到多机房容灾,logger角色就可以部署在第三个AZ3,这个节点规格可以相对差一些,AZ1和AZ2通常要求用专线连接,网络延迟不能太高。类似的,还可以做五地三中心的部署。
分布式事务是分布式数据库的必备功能。我们在CN节点上发起一个事务,这个事务内可能涉及到多个节点的DN数据,如何保证它的ACID特性?PolarDB-X提供的解决方案是MVCC+TSO+2PC。有了MVCC以后就可以很容易获取到一致的读视图;为了达到全局一致的MVCC,还需要在集群中引入TSO组件,它负责给所有CN节点分配时间戳。它部署在GMS模块上,通过Paxos保证高可用。
PolarDB-X的存储主要是基于InnoDB开发,如何让InnoDB存储引擎也适用这套机制呢?我们为InnoDB引入了分布式时间戳的概念,通过事务ID就可以找到对应的写入时间戳,利用时间戳就可以用MVCC判断可行性。这套做法最大的优势是可以在不加锁的情况下满足读一致性,性能相比2PL的实现有很大优势。
全局二级索引也是对于分布式数据库很重要的功能。举个例子,电商系统中有个订单表,传统的分库分表做法需要选择一个拆分维度,如果是以买家维度拆分,买家的下单和查询就比较快,如果是卖家维度拆分,卖家侧的查询就比较快。那么到底选哪一个呢?通常的做法是,主库采用买家拆分,并用一个异步同步链路将数据同步到卖家库,卖家库以卖家维度拆分。业务根据需要选择买家。
全局二级索引也是对于分布式数据库很重要的功能。举个例子,电商系统中有个订单表,传统的分库分表做法需要选择一个拆分维度,如果是以买家维度拆分,买家的下单和查询就比较快,如果是卖家维度拆分,卖家侧的查询就比较快。那么到底选哪一个呢?通常的做法是,主库采用买家拆分,并用一个异步同步链路将数据同步到卖家库,卖家库以卖家维度拆分。业务根据需要选择买家库或卖家库进行查询。在PolarDB-X中解决这个问题变得非常轻松,甚至可以先不去考虑以什么方式进行拆分,直接以主键拆分即可,然后以卖家和买家ID分别创建全局索引。这样一来,无论是买家还是卖家侧的查询,都可以借助索引很快查到。
索引和主表可能在不同的节点上,因此需要分布式事务来保证修改的原子性。读取时也一样,比如要访问的列不在索引上(未覆盖),需要回表,就需要借助分布式事务的一致性读能力。索引选择也是必不可少的功能,PolarDB-X的优化器是基于代价的优化器,它会估算每一种访问路径(Access Path)的代价,选择其中代价最低的计划执行。
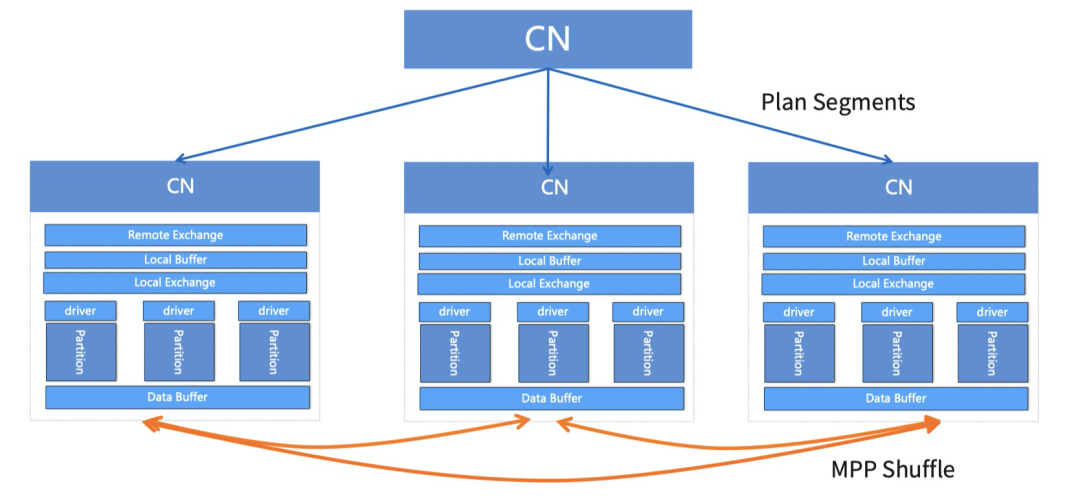
傅宇紧接着对HTAP相关功能做了重点介绍。HTAP集群的部署相比之前要多出了只读集群部分(图中右半部分),其架构与主集群类似。只读集群的DN数据由主集群同步而来。只读集群的CN节点互相之间可以通讯,可以进行MPP分布式计算。如果发现当前查询比较复杂,PolarDB-X可以将其路由到只读集群中,与主集群物理隔离。
PolarDB-X的优化器和执行器也对HTAP做了支持,例如,优化器除了负责索引选择、下推等,在AP方面也做了很多优化,比如查询关联化、物理算法的选择等,这些都是通过优化器完成的。优化器可以分为两个主要阶段,一个是查询改写,是基于规则的启发式优化,另一个是基于代价的优化阶段。如果优化器判断执行计划的代价较高,会将其输入到MPP优化阶段,使之生成分布式的物理集群计划,再交由MPP执行器执行。
上图是MPP执行器工作流程的大致演绎,当前查询所在的CN节点将执行计划的多个分片发给其他CN节点,共同进行计算。相比于其他相似的产品,PolarDB-X的执行器支持时间片调度,这是为了让AP/TP的查询执行具有不同优先级,如果同时存在TP/AP负载,TP请求先于AP请求调度。
性能方面,TPC-C和TPC-H是常见的数据库性能Benchmark,PolarDB-X都是有明显的优势,在TPC-C中,相比于另外两个竞品有接近于三倍的提升,TPCH中,相比于MySQL原本的计算还是有20倍的提升。
最后,傅宇演示了HTAP混合场景,起始只有TPC-C的流量,它的吞吐量是平稳的。之后加入TPC-H流量,可以看到TPC-C的吞吐量发生抖动,这时如果开启读写分离,TPC-C流量又恢复了之前的平稳。
责任编辑:吴昊
为您推荐
阿里云手机100G存储被指噱头 安全性遭质疑
“下一个十年所做的事情就是云手机”。在不久前的中国互联网大会上,阿里巴巴集团主席马云如此表示。但即将推小米手机的雷军却认为,手机内置100G云存储只是噱头。云手机很大程度上不能单纯由终端本身的优劣所决定,其背后的云平台乃至管道支持是否“给力”,才是关键所在。云计算、云终端、云服务,云里雾里,一片云山雾罩。当前,“云”成为企业现在标榜自己具有高科技技术的最时髦的词。到底云是什么,阿里云手机是这样解释的,通过免费提供一个最高可达100G的云存储空间,用户可以用来同步联系人、短信、通话记录、照片、便签等。用户可以直接调用多种应用,而无需把软件下载安装到本地。从这些解释中可以看出,云平台可以把重要文件
传阿里云无线并入天宇朗通 荣秀丽任CEO
凤凰网科技讯1月31日下午消息,丁香园CTO、贝塔咖啡共同创建人冯大辉在微博上透露,阿里云无线并入天宇,天语手机董事长荣秀丽任CEO,王坚任CTO。对此消息,凤凰网科技致电阿里巴巴相关负责人,对此事不予置评。而天宇方面也未回应。此前有媒体报道称,阿里巴巴与天宇双方就入资一事商谈逾一年,具体结果或于2月敲定。中国移动安徽公司浏览器基地筹备办公室主任盛鸿彬表示,互联网公司与传统IT公司相互收购将成为常态。以用户需求和体验为中心,云和端的紧密结合是大趋势。天宇朗通作为老牌公司具有丰富的终端设计开发经验,尤其是在硬件和固件方面,有能力帮助阿里云更好地落地人间。分析人士认为,互联网公司涉足手机行业已经不

