对于像Netflix这样服务上亿用户的软件服务提供商来说,服务运营是非常复杂的。按照传统的做法,复杂的事情需要专业的分工,于是整个软件生命周期会有设计、开发、测试、部署、运营、支持等不同的术业有专攻的团队和角色进行配合。但是这种做法会增加沟通损耗,导致问题经常被踢皮球。于是Netflix在实验中实践出了一套采用DevOps原则的混合模型:全周期开发者模式——谁开发的业务谁来运营,谁出的问题谁负责。同时设立了集中化团队来支撑不同的DevOps团队的公共需求。
2012年的时候在Netflix运营一项关键服务是很费力的。开发感觉就像在湿沙中行走。金丝雀部署变成了对耐心的测试(“一周的金丝雀测试都没问题发生所以我们继续推进吧”)而不是正确的功能。研究问题就好像橡皮球一样在团队之间被踢来踢去,很难抓住根源,想要阻止大家不再踢皮球更是难上加难。
时间快进到2018年,Netflix已经发展到拥有1.25亿的全球会员,每天的浏览量超过了140万小时。我们已经在改进开发运营方面进行了显著投入。一路走来我们试验了很多服务开发和运营的方案。在此,我们愿意把其中一种我们内部用得相对普遍的方案,包括它的优缺点拿出来跟大家分享。我们希望我们的经验分享能给大家一点启发并且讨论出可能的替代方案。
一支团队的旅程
Edge Engineering(边缘工程)负责AWS服务的第一层,必须为Netflix的流媒体服务正常工作准备就绪。在过去,Edge Engineering有专注运营的团队以及SRE(网站可靠性工程师)专家,他们负责软件生命周期的部署+运营+支撑这部分。发布新功能意味着开发跟运营团队要协调指标、告警及容量考虑等东西,然后再把代码交给运营团队部署和运营。要想高效运行代码并支持合作伙伴,运营团队需要持续接受新功能和修补bug的培训。拥有一支独立运营团队的主要好处是在一切正常的时候对开发者的干扰没那么多。
可当情况进展不畅时,成本就会提高。开发和运营/SRE人员之间的沟通和知识转移是有损耗的,调试问题或者回答伙伴问题需要额外的来回。部署问题因为运营团队对部署的变更没那么多直接知识,所以检测和解决需要更多的时间。代码完成与部署之间的鸿沟变得更大,发布往往是以周为量级而不是日。反馈从运营发起,这帮人直接经历了缺少告警/监控或者性能问题及时延增加这样的痛苦,然后再传递到开发人员这里时问题已经是二手了。
为了改善这种情况,Edge Engineering实验了一种混合模型,就是开发人员可以在需要的时候自己推送代码,同时负责非高峰期的生产问题和支持请求。这改善了开发者的反馈和学习周期。但这会出现部分的责任不到位的问题。比方说,即便开发者可以自己部署和调试管道破损,他们往往也会交给运营发布专家处理。对于聚焦运营的人来说,他们对日常工作有积极性,但是很难会把无需别人依赖自己的自动化放在优先考虑的位置。
为了寻找更好的解决办法,我们退后一步决定从第一性原理开始。我们究竟想实现什么?以及为什么我们不能成功?
软件生命周期
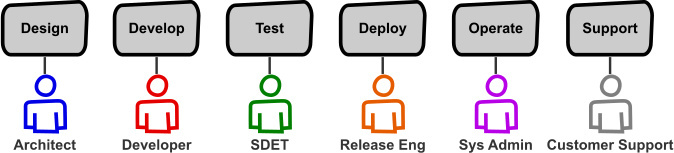
软件生命周期的目的是优化“时间价值”,有效地将想法转化为替客户做出产品和服务。开发和运行软件服务涉及到一系列的责任:
软件开发生命周期组件
我们一直在细分这些责任。极端情况下,这意味着每一个职能领域都由不同的人/角色负责:
软件开发生命周期专家
这些专门的角色在每一个细分领域内创造出了效能,但是却有可能造成整个生命周期的低效。专家在其聚焦的领域发展专业知识并针对该领域的需要进行优化。他们在解决特定领域的难题上变得越来越高效。但是软件需要整个生命周期来为客户提供价值。各自精通生命周期的一小块的专家团队反而可能会制造出烟囱导致整个端到端流程放缓。将不同的专家组成一个团队能减少烟囱,但让不同的人负责各自角色又增加了沟通负担,引入了瓶颈,并且抑制反馈回环的效能。
运营你开发的东西
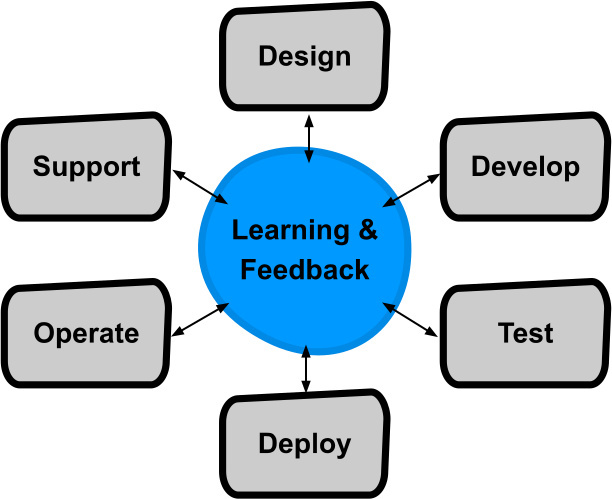
为了反思我们的做法,我们从开发运营(devops)运动的原则总获取灵感。我们可以通过打破烟囱并鼓励分享整个软件开发周期的所有权来优化学习和反馈:
支持devops原则的软件开发生命周期
“运营你开发的东西”通过让开发系统的团队也负责系统的运营和支持来践行devops原则。把这个责任分摊给每一支开发团队,而不是外化它,这样就建立直接反馈回环并且把激励给统一起来。感受到运营痛苦的团队被赋权通过改变系统设计或代码来治疗这种痛苦;他们要负责这两种职能。每一支开发团队都要负责部署问题、性能bug、能力规划、告警差异、伙伴支持等等。
利用开发者工具扩张
对整个开发生命周期的所有权给软件开发者显著增加了负担。这就需要有简化和自动化共同开发需求的工具来减轻负担。比方说,如果软件开发者预期要管理服务的回滚的话,就要有丰富的工具既能检测到问题并予以告警,又能辅助进行回滚才行。
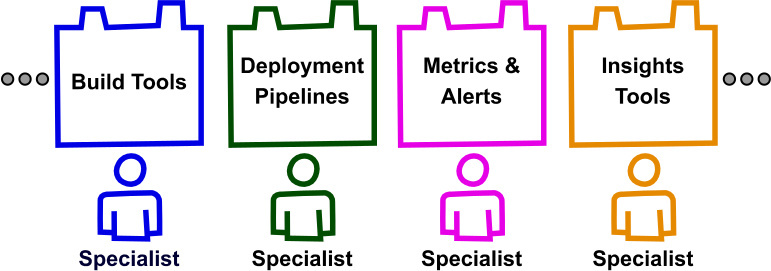
Netflix建立了集中化团队(比如Cloud Platform、Performance & Reliability Engineering以及Engineering Tools)来解决每一支开发团队都会遇到的问题,其使命是开发公共工具和基础设施。这些集中化团队将自己的专业知识变成了可重用的建构块,充当了力量倍增器的作用。比方说:
专家创建可重用的工具
有了这些工具在手,开发团队就可以专注地解决自身特定产品领域的问题。当额外的工具需求产生时,集中化团队会评估多个开发团队是否也有这些需求。如果有,接着就要协作。有时候这些局部需求太过特殊而无法获得集中化的投入。在这种情况下开发团队就要决定其需求是否重要到需要自己解决。
对类似问题在局部与集中投资间进行平衡是我们的方案当中最棘手的地方。按照我们的经验寻找开发需求的新颖解决方案的好处,是值得冒险让多支团队同时开发在将来殊途同归的解决方案的。沟通与协调是成功的关键。通过协调好需求及其共性,我们就能更好地将投资与跨开发团队的好处进行匹配。
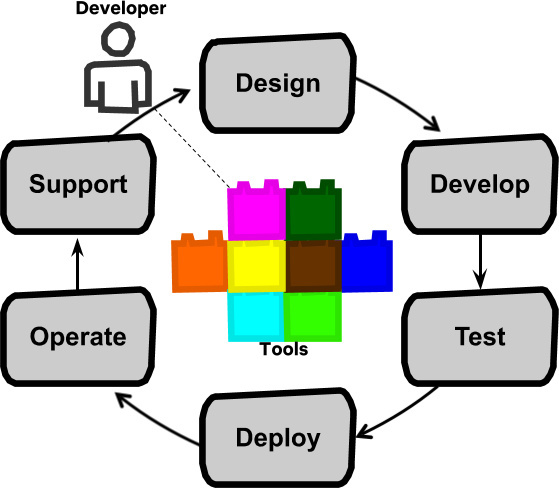
全周期开发者
把所有这些想法凑到一起,我们就得出了这么一个模式,在配备了出色的开发者生产力工具之后,开发团队将负责整个软件生命周期:包括设计、开发、测试、部署、运营以及支持。
被赋能的全周期开发者
全周期开发者需要熟悉软件生命周期各个领域并且高效。对于很多不熟悉Netflix的开发者来说,这意味着要在自己之前不怎么关注的领域加把劲。我们开设有dev新兵训练营及其他持续培训形式来灌输这种知识并培养技能。知识是必要非充分条件;部署管道和监控还需要有易用的工具才能支撑高效的全周期开发运营。
全周期开发者把工程规范应用到生命周期的各个领域。他们从开发者的角度去评估问题,会提出类似“我如何才能自动化该系统运营所需的东西?”以及“什么样的自服务工具能让我的伙伴回答他们的问题而不需要我的参与?”优先考虑聚焦系统的办法而不是聚焦于人的办法,优先考虑自动化而不是手工,这帮助了我们团队实现伸缩性。
转向全周期开发者模式需要理念的转变。一些开发者认为设计+开发,或者有时候测试才是创造价值的主要手段。这会导致一种反模式,认为运营是分心的事情,更喜欢对运营和支持问题进行短期性质的修补以便能够回到自己“真正的工作”上去。但是全周期开发者这项“真正的工作”是利用他们的软件开发知识去解决全生命周期的问题。全周期开发者要像SWE、SDET以及SRE一样思考和行动。有时候他们要创建软件去解决商业问题,有时候他们写相应的测试用例,还有些时候他们会对系统的运营方面进行自动化。
这一模式要想取得成功,团队必须为它所带来的价值做奉献并且要认识到所需的成本。团队需要预留合理的人手去管理开发和部署,处理生产问题,并且对伙伴的支持请求作出响应。需要投入时间到培训上。要利用好工具并且投资于工具。需要跟集中化团队培养合作关系来创建出可重用的组件和解决方案。规划和回顾阶段要考虑到生命周期的各个领域。除了商业项目以外,像自动化告警响应和开发自服务伙伴支持工具这样的投资需要优先考虑。有了合适的人力、恰当的优先次序,再加上合作关系,团队就能成功地运营自己开发的东西。没有这些,团队就会有负担过重精疲力竭的风险。
在Netflix之外的地方应用这一模式需要进行必要的调整。开发团队之间的共同问题可能是类似的——比如持续交付管道的需求,比如监控/可观察性等等。但很多公司并没有像Netflix这样有足够的人力投资到集中化团队上,或者也不需要Netflix这种规模导致的复杂性。Netflix的工具往往是开源的,所以一开始你想尝试一下也正常。不过这些问题其他的开源和SaaS解决方案也能满足大多数公司的需求。先从分析潜在价值和计算成本开始没然后再进行观念转变。评估你需要什么,小心不要引入不必要的复杂性。
权衡利弊
技术圈有很丰富的手段来解决开放和运营需求(延伸阅读:devops拓扑)。这里描述的全周期模型在Netflix很普遍,但这种模式也有缺点。在选择一种模式前先了解其中的利弊可以提高成功的几率。
在全周期模式下,一个人要管的事情变宽了变多了。而一些开发者偏向于专注成为比较狭窄的领域的世界级专家,在一些领域我们也是需要那种类型的专家的。对于那些专家来说,需要一专多能,对每个领域都懂一些的要求可能会感觉不太舒服而且有时候勉为其难。有些人宁愿呆在需要深厚知识不需要持续扩展广度的领域,我们也支持他们去虚招这样的角色;有的则享受并且欢迎承担更广的责任。
根据我们开发和运营基于云的系统的经验,我们见识过哪些重视拥有全周期所需的广度的开发者的效能。但是这种广度增加了每一位开发者的认知负荷,这意味着团队每周将比仅关注一个领域要平衡更多的优先事项。为此我们采取了随时待命的轮转来缓解这一点:即让开发者轮流分担部署+运营+支持责任。做得不好的情况下,就会出现人人都在当救火队员去处理生产问题等高中断的情况,导致所有人精疲力竭。
工具和自动化有助于扩展专业知识,但没有一项工具能解决开发者生产力和运营领域的每一个问题。Netflix有集中化团队支撑的现成的一套工具和实践。我们不强求其他团队一定要用这些,但是通过确保开发和运营采用这些技术的体验要比不用好得多来鼓励他们采用。我们的办法不好之处在于“每一支团队将每一项工具的每一个功能用到其最重要的需求”上这个理想几乎是不可能实现的。需要意识到我们集中化团队解决方案的投资回报需要努力、协调以及持续适配。
结论
从2012年走到今天经历了种种实验、学习和适配的过程。Edge Engineering的早期经历刺激了寻找更好模式的需求,从此全周期开发者模式就被我们积极地应用到今天。部署是日常,进行得很频繁,金丝雀行动只需要数小时而不是数日了,开发者可以迅速调研问题作出变更而不是在团队之间踢皮球。其他的团队也看到了类似的好处。然而,我们认识到我们是通过应用替代方案并从中学习才走到今天的。我们预期将来的需求还会推动进一步的演进。
原文链接:https://medium.com/netflix-techblog/full-cycle-developers-at-netflix-a08c31f83249
责任编辑:张晓宝