
刚刚得到的消息,科技汽车公司特斯拉宣布计算机视觉著名学者 Andrej Karpathy 加盟,他已成为该公司自动驾驶研究部门的一员。在此之前,Karpathy 是伊隆·马斯克旗下的人工智能研究机构 OpenAI 的研究者。这位毕业于斯坦福大学的计算机视觉专家拥有人工智能领域的丰富履历,他在博士期间曾师从于著名学者李飞飞,研究卷积/循环神经网络架构与计算机视觉应用。
在学习期间,Andrej Karpathy 还共同构建了斯坦福大学最受尊敬的深度学习教程,他在斯坦福大学的研究着重于构建一个神经网络系统,通过识别图像中离散的特征点用自然语言对图片进行标注。此外,他还构建了一个反向系统,通过用户描述的自然语言(如「白色网球鞋」)来搜索图片库中的图像。
从斯坦福毕业后,Karpathy 曾在谷歌研究院、DeepMind 等公司和机构实习,他的研究专注于深度学习。他在计算机视觉领域的专长显然被特斯拉视为巨大的财富——这家著名公司一直试图打造面向未来的自动驾驶技术。
Andrej Karpathy 在特斯拉的新职位是:人工智能和自动驾驶视觉总监(Director of AI and Autopilot Vision),特斯拉表示,Karpathy 将直接向马斯克负责,但同时也会与特斯拉副总裁、负责自动驾驶硬件与软件工程的 Jim Keller 共同工作。
特斯拉宣布 Andrej Karpathy 加盟的声明如下:
Andrej Karpathy,世界一流的计算机视觉和深度学习专家之一,现在已经以人工智能和无人驾驶视觉总监的身份加入了特斯拉,可以向 Elon Musk 直接进行汇报。Andrej 曾经通过对 ImageNet 的研发给予计算机以视觉,通过对生成模型的开发给予计算机以想象力,并且通过强化学习给予其浏览互联网的能力。
Andrej 在斯坦福大学拿到了他的计算机视觉博士学位,在那里他就可以应用深度神经网络来推导出图像的复合形式。比如,不仅仅能简单地识别图片里有一只猫,还能识别出这是一个「橙色斑点」猫,正骑在一个棕色木板和红色轮子制成的滑板上。他也创办并且教授了「用于视觉识别的卷积神经网络」(「Convolutional Neural Networks for Visual Recognition」)这门课程,这是斯坦福大学的第一个深度学习课程,直到现在仍然处于业内领先地位。(相关课程链接:http://cs231n.stanford.edu/2016/)(http://cs231n.stanford.edu/2016/%EF%BC%89)
Andrej 将会和 Jim Keller 紧密配合,后者现在已经全权负责无人驾驶的硬件和软件开发。
Karpathy 的个人简历时间线
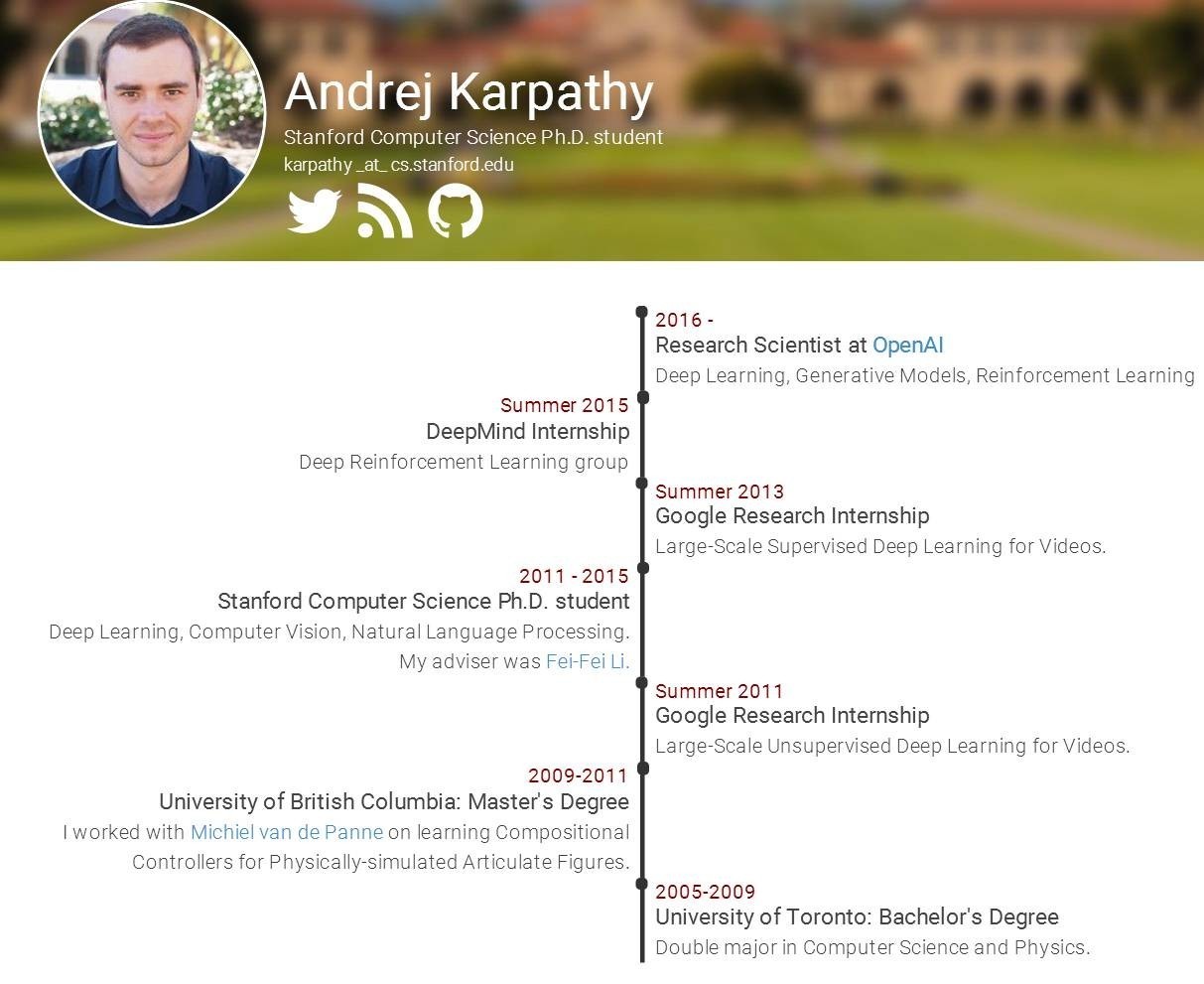
个人简介:Andrej Karpathy 是深度学习计算机视觉领域、生成式模型与强化学习领域的研究员。博士期间师从李飞飞研究卷积/循环神经网络架构,以及它们在计算机视觉、自然语言处理以及二者交叉领域的应用。在读博期间,两次在谷歌实习,研究在 Youtube 视频上的大规模特征学习,2015 年在 DeepMind 实习,研究深度强化学习。与李飞飞一起工作时,设计、教授了新的斯坦福课程《卷积网络进行视觉识别(CS231n)》。博士毕业论文为《CONNECTING IMAGES AND NATURAL LANGUAGE》。
论文:连接图像与自然语言(CONNECTING IMAGES AND NATURAL LANGUAGE)
论文链接:http://cs.stanford.edu/people/karpathy/main.pdf

审核导师
摘要:人工智能领域的一个长期目标是开发能够感知和理解我们周围丰富的视觉世界,并能使用自然语言与我们进行关于其的交流的代理。由于近些年来计算基础设施、数据收集和算法的发展,人们在这一目标的实现上已经取得了显著的进步。这些进步在视觉识别上尤为迅速——现在计算机已能以可与人类媲美的表现对图像进行分类,甚至在一些情况下超越人类,比如识别狗的品种。但是,尽管有许多激动人心的进展,但大部分视觉识别方面的进步仍然是在给一张图像分配一个或多个离散的标签(如,人、船、键盘等等)方面。
在这篇学位论文中,我们开发了让我们可以将视觉数据领域和自然语言话语领域连接起来的模型和技术,从而让我们可以实现两个领域中元素的互译。具体来说,首先我们引入了一个可以同时将图像和句子嵌入到一个共有的多模态嵌入空间(multi-modal embedding space)中的模型。然后这个空间让我们可以识别描绘了一个任意句子描述的图像,而且反过来我们还可以找出描述任意图像的句子。其次,我们还开发了一个图像描述模型(image captioning model),该模型可以根据输入其的图像直接生成一个句子描述——该描述并不局限于人工编写的有限选择集合。最后,我们描述了一个可以定位和描述图像中所有显著部分的模型。我们的研究表明这个模型还可以反向使用:以任意描述(如:白色网球鞋)作为输入,然后有效地在一个大型的图像集合中定位其所描述的概念。我们认为这些模型、它们内部所使用的技术以及它们可以带来的交互是实现人工智能之路上的一块垫脚石,而且图像和自然语言之间的连接也能带来许多实用的益处和马上就有价值的应用。

从建模的角度来看,我们的贡献不在于设计和展现了能以复杂的处理流程处理图像和句子的明确算法,而在于卷积和循环神经网络架构的混合设计,这种设计可以在一个单个网络中将视觉数据和自然语言话语连接起来。因此,图像、句子和关联它们的多模态嵌入结构的计算处理会在优化损失函数的过程中自动涌现,该优化考虑网络在图像及其描述的训练数据集上的参数。这种方法享有许多神经网络的优点,其中包括简单的均质计算的使用,这让其易于在硬件上实现并行;以及强大的性能——由于端到端训练(end-to-end training)可以将这个问题表示成单个优化问题,其中该模型的所有组件都具有一个相同的最终目标。我们的研究表明我们的模型在需要图像和自然语言的联合处理的任务中推进了当前最佳的表现,而且我们可以一种能促进对该网络的预测的可解读视觉检查的方式来设计这一架构。
本文为机器之心编译,转载请联系本公众号获得授权。
为您推荐

美国国家公路交通安全管理局(NHTSA)正在调查特斯拉Model S五月份的致死事故。通常情况下,这样一起事故虽然对受难者的亲友而言是非常悲痛的,但也不至于招来这么高级别的调查。可是,在这起案件中,这是一辆使用Autopilot自动驾驶系统的特斯拉汽车。Autopilot通过控制传感器和计算机,极大地分担了司机的驾驶压力。据特斯拉称,驾驶者和传感器都没有发现

