我常对学生讲,互联网真是个好东西,它为年轻人提供了绝佳的施展舞台和成功的技术条件,那里有无穷的宝藏,数不清的成功机会。有不少学生听了这个说法并不理解,他们往往认为互联网不就是个社交平台吗?除了看看新闻、读读博客、发发电邮、灌灌论坛还能干啥?今天我讲的这个故事,也许能帮助你了解互联网的好处,同时也普及一些数据挖掘、统计分析、机器学习方面的科学知识。
电子邮件的出现极大地影响了邮局收发传统信件的业务;大容量光盘DVD的出现影响了电影院的生意;租一盘DVD录像光碟就可以坐在家里舒舒服服地看电影,同一部电影还可以反复看,租金又相对很便宜,所以各种各样的出租录像光碟的商店如雨后春笋,多如牛毛。在如此激烈竞争的市场里,居然会冒出一个利用互联网的 影碟出租网站叫 NETFLIX,而且经营得十分成功,打垮了许多传统的影碟出租商店,最后连老牌影碟出租连锁店百事达(Blockbuster) 也不得不屈尊求教,学习 NETFLIX 的商业模式。
NETFLIX 是如何成功的?俗话说,把戏就隔一张纸。NETFLIX 成功的秘诀其实就是一个小小的创意:租一次,随便看;不限租期。这就像是从传统的按菜单点菜的饭店到食客自选的自助餐厅,顾客可以随便选,随便吃,吃到饱。1997年,NETFLIX 首创这种商业模式,用户支付固定的月租费,在NETFLIX 网站上选择自己想看的电影之后,这些电影光碟就会寄到你家,收到之后你爱看多久就看多久,没有期限,等到看满意后再用 NETFLIX 附上的免费回邮信封寄回,然后下一张电影光碟就会接着寄来。
就是这样一个小小的创意,为 NETFLIX 带来了六百七十万顾客,出租九万张影碟的业务量,它还能向顾客提供四千多部影片或电视剧的在线观看服务。业务发展了,财大气粗了,NETFLIX 就开始琢磨怎样调动观众的积极性,对看过的电影进行网上在线评分,根据用户的个人偏好,再为他们及时推荐新推出的电影。
为此,NETFLIX 设计开发了一个电影推荐系统叫 Cinematch,这是一个智能预测系统,它能够根据用户以前的评分数据预测到这位顾客可能喜欢什么样的主题和风格,等新电影发行后马上为相应的用户群 体进行推荐。可是这个推荐系统的智能水平有限,准确度不高,不能令人满意。
采用传统的方法,NETFLIX 可以雇用新的计算机软件设计人员,改进已有的 Cinematch 系统,或者另起炉灶,开发新的电脑软件系统。但是,NETFLIX 使用了更好的方法。
2006年, NETFLIX 对外宣布,他们要设立一项大赛,公开征集电影推荐系统的最佳电脑算法,第一个能把现有推荐系统的准确率提高 10% 的参赛者将获得一百万美元的奖金。2009 年 9 月 21 日,来自全世界 186 个国家的四万多个参赛团队经过近三年的较量,终于有了结果。一个由工程师和统计学家组成的七人团队夺得了大奖,拿到了那张百万美元的超大支票,获奖的照片如下:
在介绍获奖团队之前让我们先来算一笔账。看到上图的那七名获奖者了吗?他们个个都是专家、精英,我们到后来再详细介绍他们的算法;七位专家花三年时间拿到一百万美元,每人平均年收入是 47169 美元,还顶不上一个初出茅庐的大学生的年平均工资!
而 NETFLIX 的年收入是 14 亿美金,一年要花九千万美元用于研发项目的开支。对于这样一个大公司,三年拿出一百万美元来搞这项大赛,简直如同九牛一毛,毫不在乎;可是,这世界上奖金 达到一百万美元的算法竞赛还真是凤毛麟角。所以,这项百万美元大奖赛一经宣布,马上吸引了全世界186个国家的四万多个参赛团队。NETFLIX 简直是太聪明了,他们设立这项大奖赛可以说是名利双收,甚至是一本万利,付出一分投资,获得十分回报。
为什么这样说呢?第一,这是十分合算的研发外包。如上所述,把世界上最聪明的人集合在一起,采用其中最漂亮的解决方案,结果只需要付给他们相当于大专学生的工资。
第二,这是很有创意的商业广告。由于这项比赛前所未有,奖金也高达百万美金,从而吸引了无数媒体的记者,跟踪报道,NETFLIX 的新闻满天飞,报纸上、电视上、网络上无所不在,可是 NETFLIX 却分文不拿,免费获得公关宣传,净赚不赔,恐怕就是拿出十倍于大赛奖金的钱来做广告,也难以达到如此的效果。
第三,发现人才,吸引人才。通过这三年的比赛,NETFLIX 在全世界范围内发现了一大批人才,成为他们科研开发的后备军。
难怪在这次大赛圆满结束之后,NETFLIX 立马宣布还要进行下一个百万大奖。
也许你会问:改进一个算法怎么会需要漫长的三年时间?
当时参赛的多数选手也是这么问的。当 NETFLIX 最初宣布了竞赛规则之后,许多人认为这个问题并不难,答案就像是挂在一棵矮树上的果子,似乎伸手可得。开赛后的几个月里,就有参赛者把原有的 Cinematch 算法准确性提高了5%。比赛进行一年多时,最好的答案已经非常接近9%。可是事实证明,那最后的1% 才是真正的攻坚战。
获奖团队的名字叫 BPC (BellKor's Pragmatic Chaos),它由原本是竞争对手的三个团队重新组团而成,其中的七个成员分别来自奥地利、加拿大、以色列和美国,他们的职业身份分别是电脑工程师、统计学家和人工智能专家。这七个人原来分属的三个参赛团队都是曾经保持最好成绩的顶尖团队,他们的重新组合使得 BPC的实力大增,如虎添翼。但是,直到最后参加颁奖仪式时,这七个成员在领奖台上才是第一次真正面对面握手相见。原来他们是通过互联网来进行合作的,这里又一 次显示了互联网的好处;这种跨学科、跨组织的异地合作标志着今后高效科研的方向,互联网成为科研突破的重要工具;组建国际团队、实行虚拟合作也成为科学工作者的必备能力。
获奖团队 BPC 中有两位来自于AT&T 实验室,名叫 Chris Volinsky 和 Robert Bell。 Chris 是分管 AT&T 研发的执行总管,他们参加这项为期三年的 NETFLIX 百万大奖赛利用了他们的工作时间,因此他们所获的奖金归AT&T 所有,这就是所谓的 “Work for hire” 的成果。最后,AT&T 把这笔奖金捐给了当地的教育慈善机构和中小学,以鼓励青少年从事科学、技术、工程、数学(STEM)方面的学习和工作。
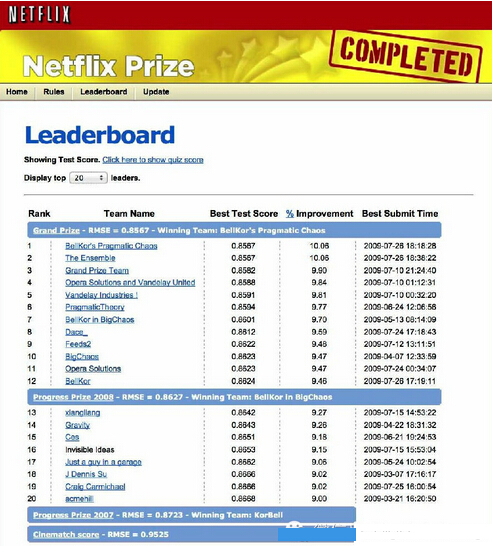
有趣的是,BPC团队最终险胜了另一个参赛团队叫The Ensemble,这个团队也是由几个名列前茅的前参赛团队重新组合而成的新团队。根据比赛规则,各个团队的得分精确到小数点后第四位,我们来看看这两个参赛小组的最后得分:
The Ensemble 的 RMSE 测试分数:0.856714,对 Cinematch 算法的改进:10.06%Bellkor's Pragmatic Chaos 的 RMSE 测试分数:0.856704,对Cinematch 算法的改进10.06%我们在后面再讨论什么是 RMSE 测试分数,仅就最终结果看,两个小组都达到并超过了 NETFLIX 的比赛目标,对原有算法的改进都超过了 10%。遗憾的是,The Ensemble 小组在提交最后结果时比 BPC 小组晚了二十分钟。“时间就是金钱”在这里有了绝妙的注解,尽管这两个团队的算法效率非常接近,因为 The Ensemble 小组晚了二十分钟,他们就与奖金无缘,只能望洋兴叹。
在总结这次赛事时,NETFLIX 的首席执行官哈庭斯说:“我们经历了一次非常激烈的比赛,参赛团队开始时候独立作战,后来协同作战,终于将影片推荐效率提高到了10% 以上。在接近比赛截止日期时,还有新的参赛作品不断快速地提交上来,让整个比赛过程变得非常曲折和惊心动魄。”要知道,把这个算法的预测效率提高10%以上可不是一件轻而易举的事,这个效率目标是 NETFLIX 的科学家们在过去的十年里面都没有办法逾越的瓶颈。
随着一百万美金大奖的颁发,NETFLIX 很快宣布了第二个百万美金大奖。
第一个百万大奖成功地解决了一个巨大的挑战,为已有评级的观众准确地预测了他们的口味和对新影片的喜好。第二个百万大奖的目标是,为那些不经常做影片评级或者根本不做评级的顾客推荐影片,这就要求使用一些隐藏着观众口味的地理数据和行为数据来进行预测。如果能解决这个问题,NETFLIX 就能够很快向新客户推荐影片,而不需要等待客户提供大量的评级数据后才能做出推荐。新的比赛用数据集有一亿条数据,包括评级数据,顾客年龄,性别,居住地区邮编,和以前观看过的影片等信息。
尽管所有的数据都是匿名的,没有办法把这些数据直接关联到 NETFLIX 的任何一位顾客,但是把顾客的年龄、性别、居住地邮编等信息公开让许多人感到不安。美国联邦政府交易委员会开始关注这项大赛对顾客隐私的损害,有一家律师事务所也代表客户递交了对NETFLIX的诉状。为了防止官司缠身,NETFLIX 在2010年3月宣布取消了第二个百万美金大奖赛。
获胜的团队的名字叫 Bellkor's Pragmatic Chaos,这个名字其实是由三个领先团队组合起来的:第一个是来自 AT&T 统计研究部的 BellKor,第二个是来自加拿大蒙特利尔的 Pragmatic Theory,第三个是来自于奥地利的 BigChaos。这种最优合并的方法也出现在其它参赛的团队里,比如这次竞赛的第二名The Ensemle 团队就有三十几名成员,他们都是在前期比赛阶段获得较好成绩的选手,后来自愿重新组合,最终在竞赛中脱颖而出。
每一位参赛者都有自己的强项和弱项,团队重组可以使参赛者之间取长补短,优化合作。这种优势互补的方法也适用于不同算法之间的合并,事实上,探讨优秀算法之间的强强结合已经成为一个很活跃的研究方向。
NETFLIX 在这次大赛中使用两组数据:第一组数据是用户对电影的评的历史数据,它有 100480507 条,这是由 480189 名用户从 1999 年到 2005 年这六年间对 17770 部电影的评级数据,这组数据是用来让参赛者进行数据挖掘和数据分析的,如下图中的绿色左段所示。这组数据是公开数据,参赛者根据对这种数据的分析、挖掘研 究而建立自己的模型和算法,并用这组数据对该算法进行训练和修正。
第二组数据被用来测试算法的可靠性和精确性,这组数据不对参赛者公开,只被裁判用来测试参赛者的算法效果。裁判们用来评判算法优劣的标准是均方根误差RMSE (root mean squared error),它是误差平均数的平方根,用来表明实际观测值和预测值之间的平均误差水平,其计算公式如下:
RMSE = .sqrt{.frac{.sum_{i=1}^{n}{( y_i-.tilde{y_i} )^{2}} }{n} }
获胜团队BPC 的算法的高明之处在于考察了用户评级数据中的时间和“频率”,用户在为影片打分时往往带有情绪影响,而情绪是与时间有关的。另外,用户的口味也许随着时间 的变化而变化;对比一位用户五年之前的打分和他最近的打分,肯定他最近的打分更为准确地反映了他当前的好恶标准,在决定他明天可能喜好哪些电影时所起的作用更大。于是BPC 团队就研究用户评分的结果与他们打分的时间以及频率之间的关系,建立了相关性模型。比如用户在周一和周五在打分时所用的标准有差异,有些用户在周日的情绪最好,这时所打的分数比平时偏高。通过这样的分析,他们能更精确地发现用户对电影的喜好口味,进而对他们打分的规律预测得更为准确。
实际的算法带有几个控制常数,需要在运行过程中精细调整,以便得出最佳的RMSE 结果。要详细解释这个算法需要许多数学准备知识,这里就不赘述了。NETFLIX 的产品总监杭特博士解释了这个算法的重要性,他说,“成功地预测客户分别喜欢哪些影片是我们服务中一个非常关键的环节。个性化推荐的极端的例子是你进入了一间有10 万部影片的商店,那些你最感兴趣的影片马上就能在你的面前排成了一排,让你尽快地发现自己要看的影片。我们用预测模型来为顾客推荐影片,相信我们的顾客一 定会非常享受这项服务”。
互联网络正从一个“搜索知识”的时代进入一个“发现知识”的时代,推荐引擎无所不在。它能为你推荐看什么电影,读什么文章,听什么音乐,买什么商品等等。搜索引擎需要一个庞大的数据库和 快速搜索算法,推荐引擎需要有一个精确的用户模型和预测决策算法;搜索引擎注重于数据,推荐引擎侧重于知识;两者相比,开发推荐引擎的难度更高。
随着算法的不断改进,推荐技术越来越普遍地应用,计算机会不会越来越多地介入我们的日常生活,甚至于控制人类?在现实生活中,有时候我们并不十分清楚自己是 否肯定需要某个东西,或者不完全清楚自己的具体需求,在这样的时候,计算机就像一位善解人意的私人秘书一样帮助你做些推荐,这是很不错的进步。当然像推荐引擎这样的技术应用如果过于泛滥,无孔不入,当人们过于依赖于机器的时候,它对人类生活的副作用也不容忽视。
责任编辑:饶军